流水线
流水线提供可视化、可定制的自动交付流水线,帮助企业缩短交付周期,提升交付效率。流水线主要功能特性如下所示。
| 特性 | 描述 |
|---|---|
| 流水线自定制 | 可根据用户项目需求,自定义流水线的阶段和任务 |
| 流水线支持任务类型 | 支多持种编任译务构类建型、代码检查、部署、流水线控制、接口测试等 |
| 流水线定时自动执行 | 系统根据用户指定的时间,自动执行用户定义的流水线任务 |
| 流水线任务构建包下载 | 用户可以选择相应任务的编译构建包下载使用 |
| 流水线执行统计查询 | 统计流水线执行进度,方便用户查看执行进展 |
| 流水线状态展示 | 展示整个流水线的状态,及其中任务的状态,并可查看日志和报告 |
| 流水线执行记录 | 系统记录流水线所有的历史执行情况,供用户查看 |
| 流水线邮件通知 | 用户可以根据需要设置流水线执行失败/成功时发送邮件通知 |
| 流水线统计功能 | 对天流水线近30天执行记录、近30天持续集成记录、近30天自动部署记录、 近30天自动发布记录、近30部署发布记录 |
| 流水线任务执行开关 | 根据用户需求,可选择流水线中的某一个或多个任务单独执行 |
| 流水线任务构建日志 | 提供任务构建日志,便于用户查看构建的详细情况,进行问题定位及相应处理 |
| 流水线任务串/并行执行 | 根据用户需求,可配置同一阶段内的任务串行执行或并行执行 |
| 流水线模板创建 | 根据用户使用场景,整合出常用的任务模板,形成多个流水线模板,方便用户快 速了解和上手流水线 |
导航点击[CI/CD/流水线],切换到流水线列表,可以查看当前项目下的所有流水线,如下图所示,可以进行查看详情、立即执行、查看执行记录、编辑、删除、克隆、停用、筛选流水线等操作。流水线页面如下图所示。
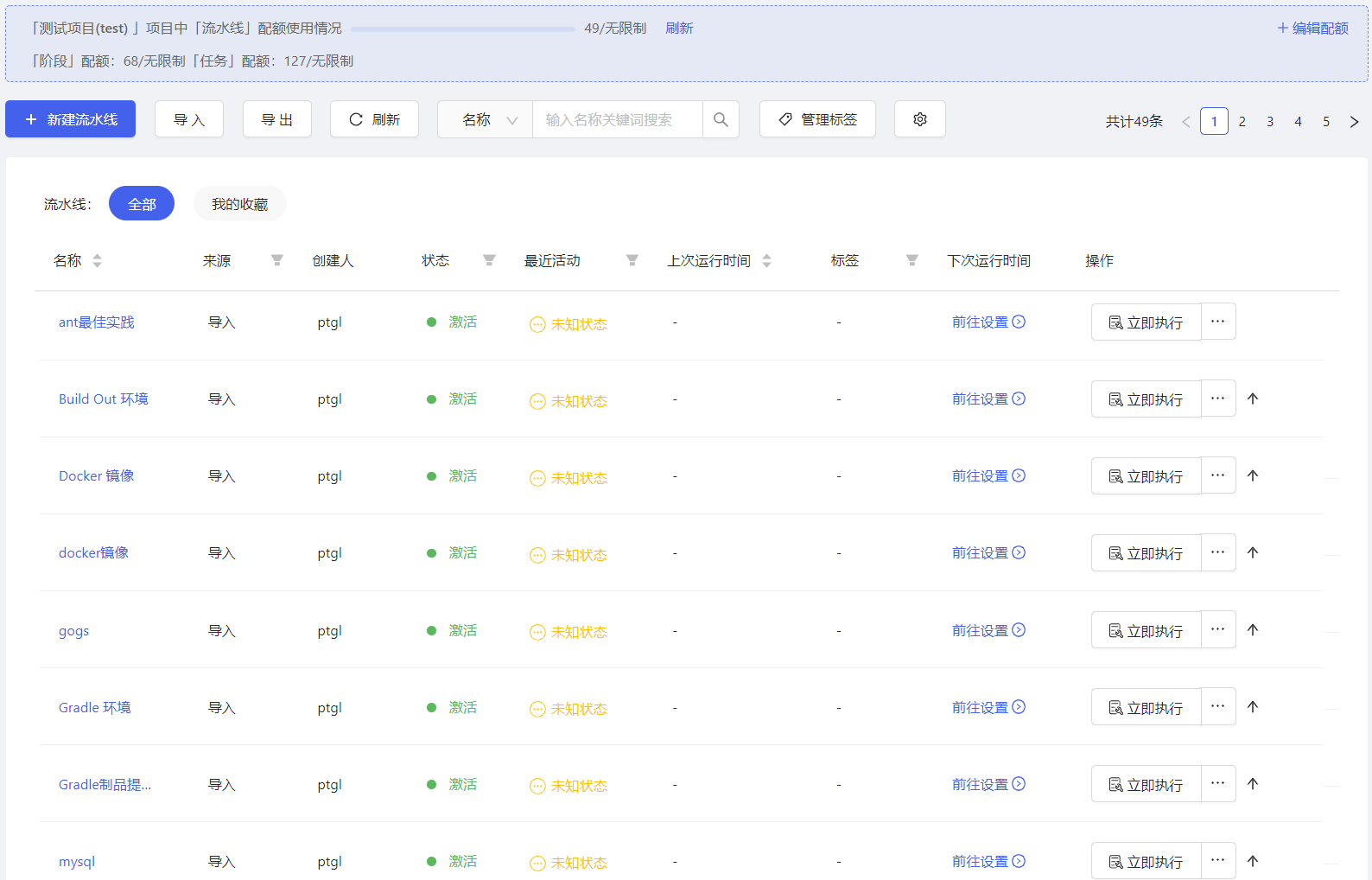
在流水线列表用户可收藏对应的流水线,配置页面如下所示。

流水线列表页面支持状态,最近活动,标签等字段筛选流水线,具体的筛选字段说明如下所示。
- 状态:停用、激活
- 最近活动:未构建、执行成功、执行失败、执行中、人工停止、系统停止、暂停、等待审批。
- 标签:按照流水线标签进行筛选
流水线支持暂停和恢复,执行此类任务时可暂停对应的执行任务,配置页面示例如下所示;执行中和等待审批的流水线可执行暂停操作,流水线恢复执行后会从暂停的任务重新开始执行流水线。停止流水线执行记录页面如下所示。
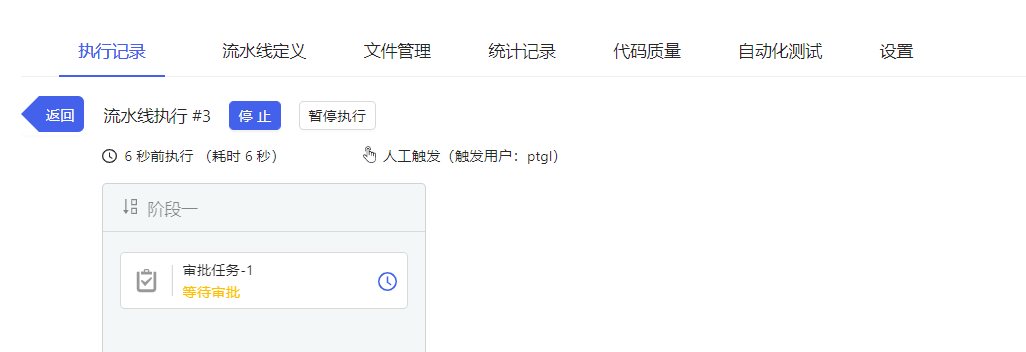
- 系统支持流水线记录暂停/恢复。
- 系统支持批量导入/导出流水线。用户可根据业务需求选择单个或者多个流水线。
相应的参数说明如下所示。
- 源项目:当前流水线所在的项目。
- 源流水线名称:要导出流水线的名称,支持多选。
新建流水线
新建流水线的操作步骤如下所示。
(1) 在左侧导航栏选择所需项目。
(2) 单击<新建流水线>按钮,填写流水线名称,选择创建方式(自由定义、模板创建、克隆流水线),根据需要设置邮件通知和标签,流水线描述,点击<确定>,即可创建成功。
如果用户在创建流水线的过程中需要存储设备,要在提前在PAAS平台配置对应的存储卷设备。
创建方式说明如下表所示。
| 创建方式 | 说明 |
|---|---|
| 自由定义 | 创建一个空白的流水线,阶段和任务都需要人工去创建并配置 |
| 模板创建 | 系统支持7种常用模板: 1)Maven最佳实践 2)Gradle最佳实践 3)Ant最佳实践 4)Maven制品提取 5)Gradle制品提取 6)Ant制品提取 7)Docker服务镜像更新模板 使用模板创建流水线时,为了保证流水线创建成功即可执行,需要将必须的参数 提前进行配置 |
| 克隆流水线 | 选择克隆已有流水线中的阶段和任务 |
添加阶段
(1) 流水线新建成功后,进入流水线定义界面,系统默认添加一个流水线阶段。
(2) 每个流水线都是由若干个阶段组成,不同阶段从左到右顺序执行,一个阶段执行结束,然后执行另一个阶段。如果有多个阶段,点击“+”,添加阶段,如下图所示。
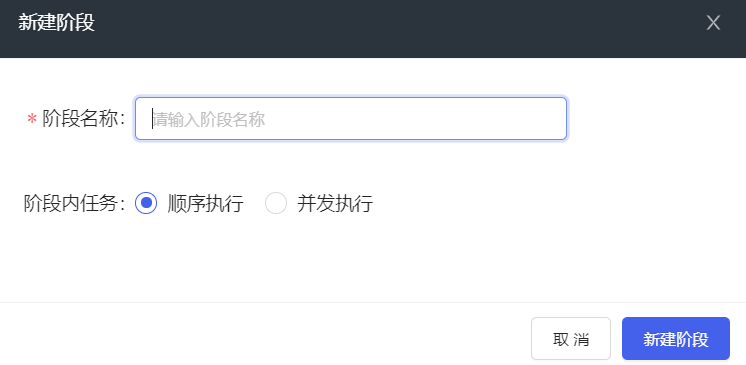
(3) 输入阶段名称,例如:“阶段一”。
(4) 选择阶段内任务执行方式,顺序执行就是从上到下,一个任务执行结束后,开始执行另一个任务;并发执行就是同时开始执行所有任务,每个任务相互之间没有关联。
(5) 点击<新建阶段>按钮完成创建。如下图所示。
新建流水线时,系统默认创建一个阶段。
添加任务
(1) 点击阶段卡片内的”+”按钮,进入选择模板页面,如下图所示。
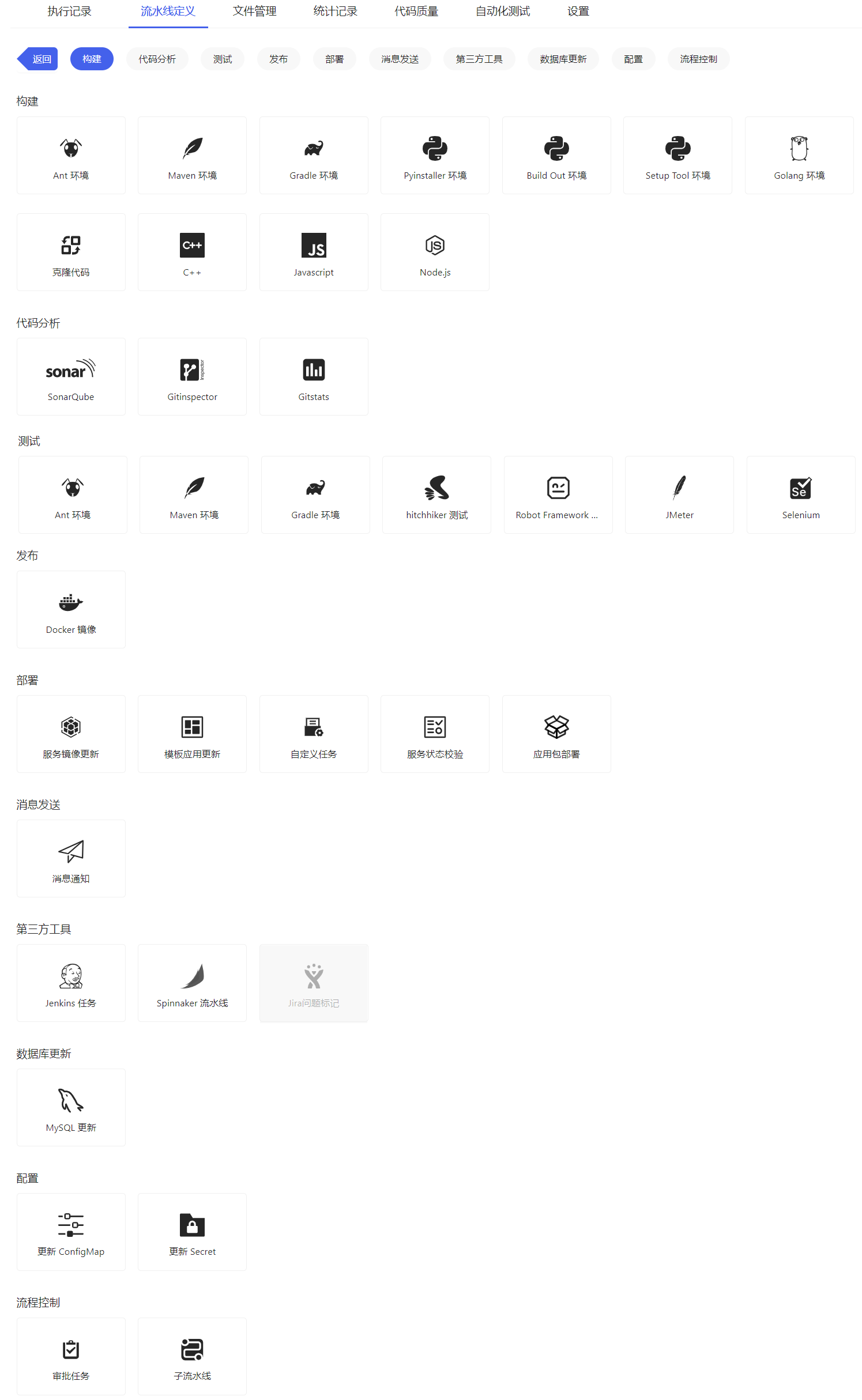
平台提供各类任务模板,例如构建、代码分析、测试、发布、部署、消息发送、第三方工具、数据库更新、配置、流程控制。各类任务模板包含的任务模板详情如下所示。
- 构建:Ant环境、Maven环境、Gradle环境、Pyinstaller环境、BuildOut环境、SetupTool环境、Golang环境、克隆代码、C++、Javascript、Node.js。
- 代码分析:SonarQube、Gitinspector、Gitstats。
- 测试:Ant环境、Maven环境、Gradle环境、hitchhiker测试、RobotFrameworkTest、JMeter、Selenium。
</li></p>``<p><li>发布:Docker镜像。 - 部署:服务镜像更新、模板应用更新、自定义任务、服务状态校验、应用包部署。
- 消息发送:消息发送。
- 第三方工具:Jenkins任务、Spinnaker、Jira问题标记。
- 数据库更新:MySQL更新。
- 配置:更新ConfigMap、更新Secret。
- 流程控制:审批任务、子流水线。
用户可以根据需要自定义任务。
对于需要用到存储卷的任务模板,用户需要提前在对应的集群项目下新建存储卷。
例如:选择“Docker镜像”模板,进入如下页面。
(2) 根据实际需要定义任务,点击<提交>即可。
(3) 已添加任务,可以通过拖动方式,调整任务顺序,如下图所示。
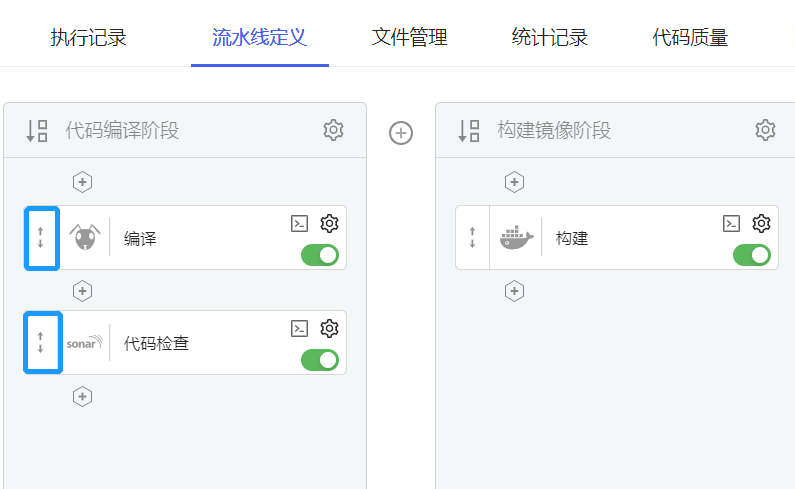
鼠标移入图中所示区域,可以拖动任务卡片。
任务模板配置详解
Docker镜像
使用场景:使用该模板用来构建Docker镜像。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前 任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- Dockerfile:可以选择使用云端Dockerfile,直接编辑,并会自动保存到平台上,或者 填写代码仓库中Dockerfile文件路径,默认识别文件名为Dockerfile。
- 构建上下文:构建上下文环境路径。
- 使用构建存储:打开开关,执行该任务时将会保存构建存储,方便下次构建。
- 仓库组类型:支持平台内镜像仓库组、自定义仓库组。
- 平台内镜像仓库组,需要先选择Harbor镜像服务,然后选择仓库组。
- 自定义仓库:平台“镜像仓库”中添加的第三方仓库,如需要添加,请移步交付中心-镜像仓库菜单操作。选择仓库组(接入平台时输入的仓库名),输入命名空间(如有,请输入)。
- 镜像名称:用户自定义,不能使用镜像仓库组已经存在的镜像名称。
- 镜像版本:可选5 种命名规范,以代码CommitID、代码分支/标签、时间戳为tag、自定义tag、流水线序号,支持 5 种命名规范组合排序。
- 系统架构类型:构建镜像依赖的CPU架构,平台支持选择AMD 64 、ARM 64 、PPC_ 64 le、s 390 x、 386 、ARM_v 6 、ARM_v 7 等类型的CPU架构。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
服务镜像更新
使用场景:当Docker镜像任务已经执行过,并用生成的镜像部署了服务,才可以设置镜像来源为构建镜像任务进行部署。
容器部署模板用于持续部署,当执行该任务时,会自动部署服务。
配置项说明:
- 选择镜像来源:支持构建镜像任务、镜像地址、镜像推送事件。
- 构建镜像任务:需要选择一个本任务之前的Docker镜像任务,将构建出的新镜像更新到服务。这里的Docker镜像任务指所在阶段顺序执行时本任务之前的任务,所在阶段并发执行时,本任务所在阶段之前阶段的任务。流水线停用或者Docker镜像任务关闭,将无法选择到相应任务。
- 镜像地址:支持选择镜像仓库和自定义仓库(平台“镜像仓库”中添加的第三方仓库)。
- 镜像推送事件:需要先设置CI触发流水线,推送镜像触发的触发规则。
- Docker镜像任务:流水线任务所在阶段顺序执行时本任务之前的任务;或者所在阶段并发执行时,本任务所在阶段之前阶段的任务。流水线停用或者Docker镜像任务关闭,将无法选择相应任务。
- 要更新的服务:选择需要更新的集群、服务、部署、容器,流水线构建新的镜像后,可以部署该服务。可以选择普通升级或者滚动升级,滚动升级可以保证服务平滑迁移。本任务仅作为更新,即镜像已初始创建过服务,可在流水线先关闭本任务,手动创建服务后开启。
- 等待时间:配置自动检测服务就绪的时长。
- 自动回滚:打勾的话,如果升级失败,则自动执行回滚,此时该任务状态为执行失败。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
模板应用更新
使用场景:满足用户使用平台CI/CD功能,持续更新部署模板应用的需求。
配置项说明:
- 选择集群:要更新模板应用的集群。
- 模板应用:PaaS平台应用模板部署的模板应用,用户也可选择新建模板应用。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
审批任务
使用场景:审批任务用于流水线内审批,可以在流水线任意位置插入审批任务,审批通过后流水线才能执行下一步。
配置项说明:
- 审批人:选择该项目中的成员。
- 发送审批邮件:勾选是否给审批人发送邮件,邮件服务器配置从全局配置中获取。
- 超时时间:设置未操作超时时间,超时之后,流水线将不再执行。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 失败重试次数:当前任务失败后重试执行的次数。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
通知消息
配置项说明:
- 任务名称:消息通知任务的名称。
- 通知组:选择PaaS平台已有的通知组,或者用户可新建所需的通知组。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:用户可设置通知消息任务在任务失败后,重复执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
Ant环境
使用场景:ApacheAnt主要用途是构建Java应用程序。您可以把ant作为流水线的一个任务,去构建Java应用程序。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表查]看集群的主机节点情况)。
- 任务失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Maven环境
使用场景:Maven同Ant一样可以作为一个流水线任务,用于构建Java应用。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含Clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Gradle环境
使用场景:Gradle同Ant一样可以作为一个流水线任务,用于构建Java应用。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
SonarQube
使用场景:平台集成了代码质量管理工具Sonarqube,您需要配置连接您的Sonarqube服务器,然后配置需要检查的项目,就可以在流水线中自动检查代码质量。
SonarQube的版本必须在6.3及其以上,否则在系统中查看扫描结果会报错,因为SonarQube官方公开的API获取扫描结果的支持版本是从6.3开始。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- SonarQube认证配置:填完验证信息,需要验证通过,连接成功之后方可使用。
- SonarQube项目配置:配置需要检查的SonarQube项目。可以填写服务器中已存在的项目或者创建一个新的项目。
- SonarQube检测结果配置:支持使用质量门状态或者代码质量关键指标自定义阈值,从而控制流水线任务执行状态。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
- 报告下载:流水线支持下载代码扫描(SonarQube)报告。
Hitchhiker测试
使用场景:hitchhiker是一款开源测试软件,用于接口和压力测试,在流水线中配置server的地址和选择已配置好的测试用例,即可进行测试任务。
配置项说明:
- hitchhiker服务器地址:输入IP地址和端口号。
- 测试用例:服务器验证通过之后,才可以选择测试用例。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:当前任务失败后重试执行的次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
Jenkins任务
使用场景:将Jenkins项目添加到流水线。
配置项说明:
- Jenkins服务器URL:输入Jenkins服务器URL。
- Jenkins账号:登录Jenkins服务器的账号。
- Jenkins密码:登录Jenkins服务器的密码。
- Jenkins项目名称:验证服务通过之后,才能选择项目。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
Spinnaker流水线
使用场景:可以通过Spinnaker流水线任务模板,将Spinnaker集成到流水线中。
配置项说明:
- SpinnakerGate服务器地址:填写SpinnakerGate服务器URL,验证通过之后才能选择Spinnaker的应用和流水线。
- Spinnaker应用:选择Spinnaker应用。
- Spinnaker流水线:选择对应的流水线。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
Pyinstaller环境
使用场景:Pyinstaller主要用途是安装有pyinstaller环境的任务模板,可以执行有关使用pyinstaller的python任务。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
BuildOut环境
使用场景:BuildOut环境是指安装了buildout工具的python环境。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
SetupTool环境
使用场景:SetupTool环境是指安装了setuptool工具的python环境。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Golang环境
使用场景:Golang环境是用来编译Golang语言。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
克隆代码
使用场景:除了默认代码源,如果还需要其它代码,可以添加一个克隆代码任务,此任务可以将需要的代码克隆到任意目录(包括存储卷)。
配置项说明:
- 代码源:选择代码仓库中已激活的项目及版本。
- 存储卷:需要添加一个代码克隆的存储卷。
- 代码克隆至:填写代码需要克隆的目录,如果是存储卷需要映射该目录。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X^86 计算或高性能计算GPU上。
自定义任务
使用场景:此任务可以用来执行Shell、Python、Ruby、PHP脚本,比如可以查看克隆代码是否成功等场景使用。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
MySQL更新
使用场景:将执行数据库更新时使用SQL脚本的动作,固化成一个流水线任务模板,便于减少人工操作,提高应用部署效率。
配置项说明:
- 数据库认证配置:数据库认证配置:连接数据库使用参数:Host、Port、User、Password(加密)、Database,支持验证数据库服务是否连通。
- 执行SQL脚本文件:上传文件或者直接输入文件内容(仅支持上传.sql格式文件),或者从代码仓库获取,可选择已激活的代码项目。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
服务状态校验
使用场景:平台支持在CD流水线中添加校验服务的功能,用于检验部署的服务启动情况,用户可以在该任务模板中配置服务信息。
配置项说明:
- 服务名称:选择想要检测的集群、服务、部署。
- 检测超时时间:指任务第一次检测到服务未就绪时,将会重复检测直到服务变为就绪状态的时间限制。
- 邮件通知:目前仅支持对单一邮箱通知。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X^86 计算或高性能计算GPU上。
C++
使用场景:此任务提供的C++的基础镜像,用户可以用此任务模板执行相关脚本。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Node.js
使用场景:此任务提供的Node.js的基础镜像,用户可以用此任务模板执行相关脚本。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
JavaScript
使用场景:此任务提供的JavaScript的基础镜像,用户可以用此任务模板执行相关脚本。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 执行CMD脚本文件:CMD脚本执行的工作目录为pipeline基础镜像的文件系统目录,包含clone的代码。可以手动输入脚本,也可以上传本地脚本文件。点击添加一个参数可以输入参数。
- 人工制品:支持提取构建容器/app目录下内容,对当前任务构建产出的文件制品进行管理,包括但不限于war、jar、tar、xar等应用包,人工制品文件可用于测试验证。
- 基础环境:基础镜像是用来提供执行当前任务的环境的,有默认的预置镜像(联系管理员新增),您也可以上传自定义镜像。基础镜像以Docker镜像的形式存在,在流水线执行过程中,会以容器形式在后台运行。
- 依赖服务:依赖服务是用来提供执行当前任务时所依赖的服务,因为是容器化部署,您需要自定义服务的环境变量。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 存储卷:单击开关,添加存储卷,注意并行任务不能使用同一个存储卷。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
更新ConfigMap
使用场景:此任务可以用来更新PaaS的服务配置ConfigMap。
配置项说明:
- 集群:选择要更新ConfigMap的已授权的集群。
- 服务配置组:要更新的ConfigMap文件所在的配置组。
- ConfigMap:选择在PaaS平台已存在的需要更新的服务配置文件。
- 更新内容:支持本地文件导入和Git仓库导入。
- 执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
应用包部署
使用场景:此任务可以用来执行PaaS的应用服务。
配置项说明:
要部署应用:选择PaaS平台已经部署的应用,实际更新应用包的应用。
应用包名称:应用服务的应用包名称。
应用包版本:支持始终部署最新上传版本、指定版本。
- 始终部署最新上传版本:部署时会从列表中选择最新上传(与应用包版本无关)的应用包进行部署。
- 指定版本:用户需从对应版本的应用包列表中指定本次更新应用服务使用的应用包。
升级策略:支持普通升级、滚动升级。
- 普通升级:会中断待更新的应用服务。
- 滚动升级:采用KubernetesRS扩容方式,不会中断应用服务。
自动回滚:启用后需要设置服务更新完成等待就绪时间,超过等待时间且服务未正常工作时应用服务则回滚到更新前。
执行节点:可以指定执行的主机节点,注意是当前集群的主机节点,也可以系统自动分配,将根据主机节点的健康和负载状态进行分配(可以通过[管理工作台/集群管理/主机列表]查看集群的主机节点情况)。
任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
允许失败:该任务失败,将不影响流水线继续执行。
自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Gitstats
使用场景:Gitstats是一个git仓库分析工具,可以帮助用户查看git仓库代码的提交状态,根据不同维度分析计算,并自动生成数据图表。
Gitstats统计的维度如下所示。
- 基本统计:项目名称、统计生成时间(以及时长)、统计生成器(GitStats)、统计涉及时间段、Age(总天数以及提交天数)、文件总数、行总数、提交总次数、提交总人数。
- 提交次数:一天内按照小时统计、一周内按天统计、一周内按小时统计、一年内按月统计、按年统计同时按月统计、按年统计以及按照所处时区提交统计。
- 作者维度:作者表格(姓名、提交占比、增加代码行数、删除代码行数、首次提交日期、最后一次提交日期、Age、提交天数),每位作者在累计每月的代码行数量(只显示前 20 位),每位作者累计每月的提交数量(只显示前 20 位),按月统计作者提交表格,按年统计作者提交表格,按照域名统计提交柱状图。
- 文件维度:文件总数、文件总行数、平均文件大小(单位是字节)、每天文件数量变化折线图、按照扩展名统计表格(扩展名、文件数量与占比、文件内行数与占比、行数与文件数量的倍数)。
- 行数维度:当前代码总行数、每天总代码行数折线图。
- 分支标签维度:分支总数、提交总数与分支总数计算平均值、分支表格(分支名称、建立分支日期、分支提交次数、提交作者名称)。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 输出方式:系统默认选中邮件服务并且邮箱地址不能为空;用户也可选择绑定PAAS平台已有的存储卷,从而实现统计结果的持久化存储。在业务应用中便捷拉取对应的统计数据。当只选中一个输出方式时,该选中项置灰,并提示至少选择一种输出方式。
- 最作者大数:用户可以设置作者统计列表中要展示的作者个数。
- TopN作者:用户可以设置作者统计列表中代码提交行数的前N个作者,并且用折线图展示。
- 按提交ID指定:如果用户关注特定的提交阶段,可以设定“提交起始版本”,“提交终止版本”多维度来统计该阶段内所有作者向git仓库提交的情况。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Gitinspector
Gitinspector可以汇总对于git仓储代码的统计信息并且进行分析。默认的以作者为单位,显示基本的统计信息,它也可以补充时间线分析,时间线分析每一位作者的工作量和活跃程度。在普通的操作下,gitinspector会显示对默认的一系列扩展名的文件进行分析的结果。
Gitinspector支持多种输出格式,支持按照文件扩展名过滤分析结果,支持按照文件扩展名扫描仓库文件,可以显示时间线统计分析图,支持多线程以提高分析速度。
配置项说明:
- 代码来源:当前任务的代码来源,平台支持选择代码源或者添加对应的存储卷为当前任务运行提供代码源,当选择存储卷时需要先添加对应的存储卷。
- 输出方式:系统默认选中邮件服务并且邮箱地址不能为空;用户也可选择绑定PAAS平台已有的存储卷,从而实现统计结果的持久化存储。在业务应用中便捷拉取对应的统计数据。当只选中一个输出方式时,该选中项置灰,并提示至少选择一种输出方式。
- 时间范围:用户可以根据业务需要设置相应的统计时间段。
- 时间线报表:用户可以选择按月或者按周生成统计报表。
- 文件扩展名:用户可以选择根据文件扩展名来生成统计报表。
- 其他配置:用户还可以列出所有的文件扩展名,其中进行统计的突出标记;选择显示作者负责的文件排行榜。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
更新Secret任务
使用场景:与ConfigMap使用场景类似,都可以用来更新PaaS的服务配置,从而让镜像和配置文件解耦,实现镜像的可移植性和可复用性。
Secret是一种加密配置,加密方式可以是加密配置文件(通过volume方式引入),也可以是加密变量(通过环境变量引入)。两种方式在创建时不区分,只在使用时区分。
配置项说明:
- 集群:选择要更新配置文件的集群,该集群需得到项目授权。
- 配置组:选择要更新的secret的配置组,即系统需要更新的secret所在的配置组。
- Secret:选择配置组下具体要更新的某个secret配置。
- Secret更新内容:要更新配置的具体内容,用户可以选择导入本地配置文件或直接输入配置文件,内容可以为任意格式和任意内容,如.XML/.Yaml/.Json/.JS等等。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X^86 计算或高性能计算GPU上。
子流水线任务
使用场景:需要用一个流水线(父流水线)去启一条或者多条流水线,同时父流水线可以检测子流水线的执行情况。
父流水线和子流水线是树形关系,流水线之间的父子关系只有在删除其中一类流水线的时候才会解除;任务中的子流水线和父流水线需在同一租户,同一集群下。所选项目可以不同。
配置项说明:
- 项目来源:在当前集群下选择要执行子流水线任务的项目,用户可以选择非当前项目。
- 流水线:在当前集群下选择不包含子流水线任务的流水线作为子流水线。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在x86计算或高性能计算GPU上。
RobotFramework
使用场景:RobotFramework一个基于Python的、可扩展的、关键字驱动的测试自动化框架,因此常用于自动化测试中。
将自动化测试脚本的代码源关联到流水线中,流水线创建RobotFrameworkTest任务,在流水线设置CI触发规则,当自动化测试脚本更新时,自动执行该条流水线,执行测试脚本。
在RobotFramework任务选择将测试结果存储在存储卷中,用户自启动一个Nginx服务挂载此存储卷,将Nginx服务的URL地址配置在任务中,即可在平台中跳转到结果页面。
配置项说明:
- 测试用例来源:用户选择要执行的测试用例的类型,可选的类型有代码源、存储卷。
- 代码源:选择对应代码类型下的代码分支。
- 存储卷:包含有代码源的测试用例存储卷。
- .robot文件路径:选择代码源中的执行脚本的路径。
- 执行文件:用户可以选择执行该代码源下所有脚本文件或者指定的部分脚本文件。
- 脚本路径:执行自动化测试脚本所在的路径,用户可以选择执行路径下所有的脚本,也可执行特定的脚本,此时填写对应的脚本名称,以空格分隔即可。
- 将自动化测试结果标记到Testlink:脚本执行的结果体现在testlink对应的列,以表明自动化测试是否执行成功。
- 测试报告名称:用户自定义配置测试报告的名称。系统将报告收集起来,用户在文件管理中可查询测试报告。
- 报表地址:nginx服务挂载上方添加的存储卷到/usr/share/nginx/html/,此处填写nginx服务地址以获取报表地址。
- 使用存储卷存放结果:用户可以选择将自动化测试的结果存放到devops和PaaS通用的存储卷,其他任务可以拉取测试结果数据,实现任务之间的互联。
- 基础运行环境镜像:选择测试用例执行的运行环境镜像。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Jmeter
应用场景:为满足流水线自动化测试中对性能测试的需求,平台提供通过CI触发自动执行JMeter性能测试脚本的任务模板,从而实现简化部署、人力与资源成本的目的。
配置项说明:
- 测试用例来源:用户选择要执行的测试用例的类型,可选的类型有代码源、存储卷。
- 代码源:选择对应代码类型下的代码分支。
- 存储卷:包含有代码源的测试用例存储卷。
- .jmx文件路径:选择代码源中的执行脚本的路径。
- 执行文件:用户可以选择执行该代码源下所有的.jmx脚本文件或者指定的.jmx脚本文件。
- 测试报告名称:用户可以选择“使用存储卷存放测试结果”,此处可选择TCE已有的存储卷或者新建存储卷,配置页面如下图所示。
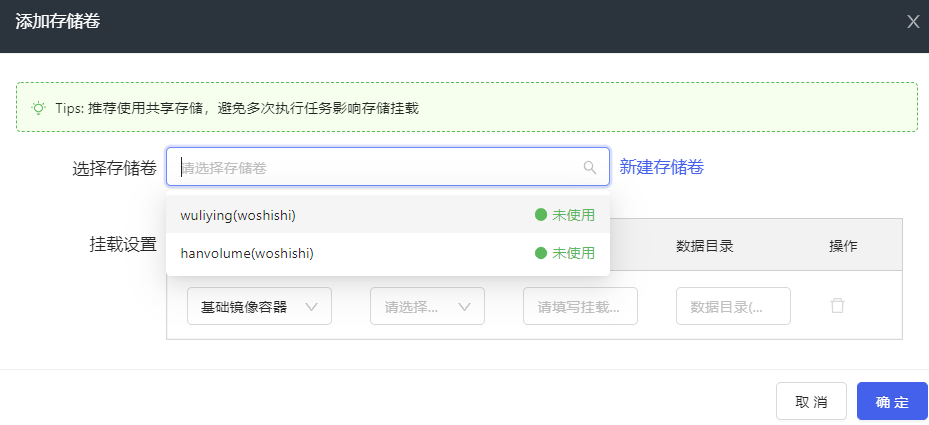
- 报表地址:nginx服务挂载上方添加的存储卷到/usr/share/nginx/html/,此处填写nginx服务地址以获取报表地址。
- 基础运行环境镜像:选择测试用例执行的运行环境镜像。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 任务失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Selenium
应用场景:为满足流水线自动化测试中对性能测试的需求,平台提供通过CI触发自动执行Selenium性能测试脚本的任务模板,从而实现简化部署、人力与资源成本的目的。
配置项说明:
- 导入测试用例:用户选择要执行的测试用例的类型,可选的类型有代码源、存储卷。
- 代码源:选择对应代码类型下的代码分支。
- 存储卷:包含有代码源的测试用例存储卷。
- .py文件路径:选择代码源中的执行脚本的路径。
- 执行文件:用户可以选择执行该代码源下所有的.py脚本或者指定.py文件。
- 测试报告名称:用户自定义配置测试报告的名称。系统将报告收集起来,用户在文件管理中可查询测试报告。
- 测试报告存放:用户可以选择“使用存储卷存放测试结果”,此处可选择TCE已有的存储卷或者新建存储卷。
- 报表地址:nginx服务挂载上方添加的存储卷到/usr/share/nginx/html/,此处填写nginx服务地址以获取报表地址。
- 基础运行环境镜像:选择测试用例执行的运行环境镜像,默认使用Selenium最新版本环境。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
Jira问题标记
应用场景:通过Jira与CI/CD流水线之间的联动将项目管理和CI/CD都融入到用户已有的DevOps的工作流中。这使得DevOps的运行存在一些影响效率的痛点。
通过自动化的方式,将每次执行包含的所有可标记解决的Jira问题自动置为“已解决”,并注入备注信息。并具备以下优势。
- 开发人员需要做的事只有提交,push,提出MR即可,jira问题的标记可以自动完成,注入备注信息。
- 测试人员可以从Jira问题的备注信息里,通过点击超链接,跳转到Gitlab的具体Commit页面,查到本次修改的内容。
- 项目管理人员可以从Jira问题的备注信息里,看到执行的流水线信息,并能跳转到流水线构建详情页,查到相应的流水线构建记录。
- 流水线用户还可以在流水线构建记录中,查找每一次的执行分别标记的Jira问题。
该功能依赖一个MinIO中间件,因此需要用户在对应的项目集群部署一个MinIO服务,部署的步骤如下所示。
(1) 登录平台后,用户选择[所有产品/中间件/应用],选择对应的集群项目,找到MinIO集群,点击<部署>按钮,进入集群部署页面,如下图所示。
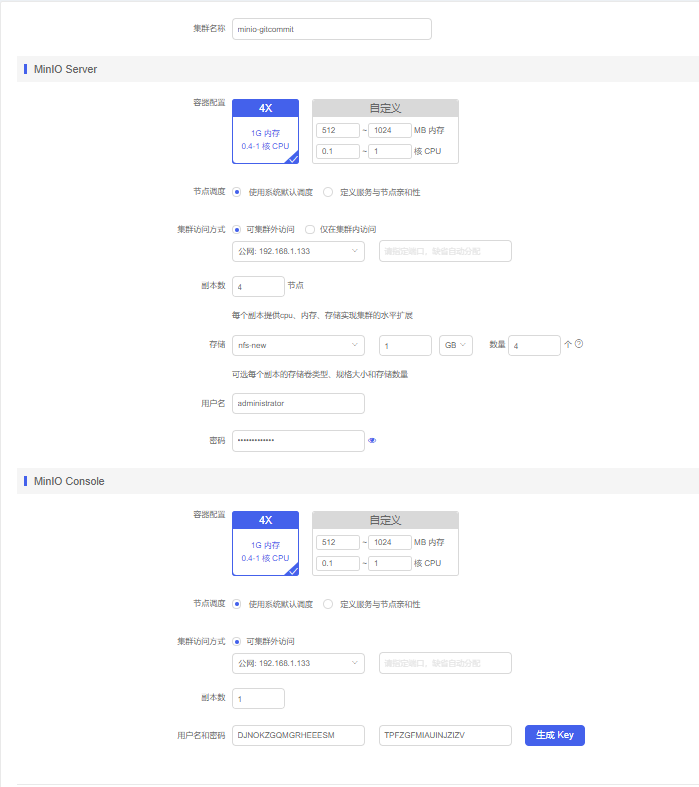
(2) 填写数据库集群名称,配置MinIOServer对应参数,配置MinIOServer容器配置,支持选择默认值和自定义容器配置。
(3) 选择节点调度方式,用户可以选择使用系统默认调度,也可以定义节点亲和性。
- 开发人员需要做的事只有提交,push,提出MR即可,jira问题的标记可以自动完成,注入备注信息。
- 系统默认调度策略指的是不允许节点端口被其他容器实例占用,不允许容器实例创建在空闲资源不足的节点服务实例与节点亲和性:亲和性定义有两个等级,必须表示强限制性的硬策略,如果没有符合条件的节点,会一直重试,一般用于服务必须满足一定运行条件,不满足就会出问题的场景。最好表示优先调度到符合条件的节点,如果没有符合条件的节点,就忽略该条件,按照正常情况调度。
- in表示调度到满足主机标签的节点,主机标签值可以多选。
亲和性规则可以设置多个,单次添加的亲和性规则之间是“且”的关系,必须同时满足设定所有的规则,每个亲和性规则之间是“或”的关系,满足其中一个亲和性规则即可。
:::
(4) 选择集群访问方式,用户可以选择“可集群外访问”,也可以选择“仅在集群内访问”。
(5) 填写MinIOServer副本节点数,选择所需的存储卷(支持RBD、NFS、local类型的存储),输入Server的用户名和对应密码。
(6) 配置MinIOConsole的容器资源大小,选择节点调度方式。
(7) 选择MinIOConsole集群访问方式,用户可以选择“可集群外访问”,也可以选择“仅在集群内访问”。
(8) 填写MinIOServer副本节点数,选择所需的存储卷(支持RBD、NFS、local类型的存储)。
(9) 输入Console的用户名和对应密码,单击<生成Key>,MinIOConsole参数配置成功,单击<确定>即可创建一个MinIO集群。
Jira问题标记配置项说明:
- 起始状态:jira问题的起始状态,用于标记Jira的开始状态。
- 执行后状态:jira问题的执行后状态,用于标记流水线执行后jira的状态。
- 执行节点:用户可以选择要执行任务的节点,也可以让系统自动分配执行任务的节点。
- 失败重试次数:支持用户设置任务失败后流水线任务的重试次数。
- 允许失败:该任务失败,将不影响流水线继续执行。
- 自定义配置:支持pipeline任务运行在X 86 计算或高性能计算GPU上。
- 流水线与jira的联动基于当前平台所处项目维度。因此需要在项目维度配置流水线要联动的jira信息,用户需在[软件工程过程管理/服务集成/JIRA]配置对应的URL及帐户密码。
- MinIO使用前用户需要在[管理工作台/集群管理]页签,对应的集群详情/集群插件中安装MinIO插件。
管理流水线
- 执行流水线:流水线定义完成后,需要执行流水线,执行流水线有五种方式:手动执行、CI触发、定时触发、镜像触发、流水线触发。支持在触发流水线后,payload事件会以参数形式传给容器,可自行在任务中按需调用。
- 手动执行:流水线列表,右侧操作点击<立即执行>或流水线详情右上角点击<立即执行>按钮,选择执行代码分支或标签,开始执行。
- 手动停止执行:如单条流水线由于某个任务执行时间过长、人为操作原因被重复执行多次,可以在执行记录tab页中手动选择关闭正在执行的流水线任务。
CI触发
(1) 流水线详情页,tab切换到设置,如下图所示。
(2) 点击<编辑>,设置CI触发和定时触发,如下图所示。
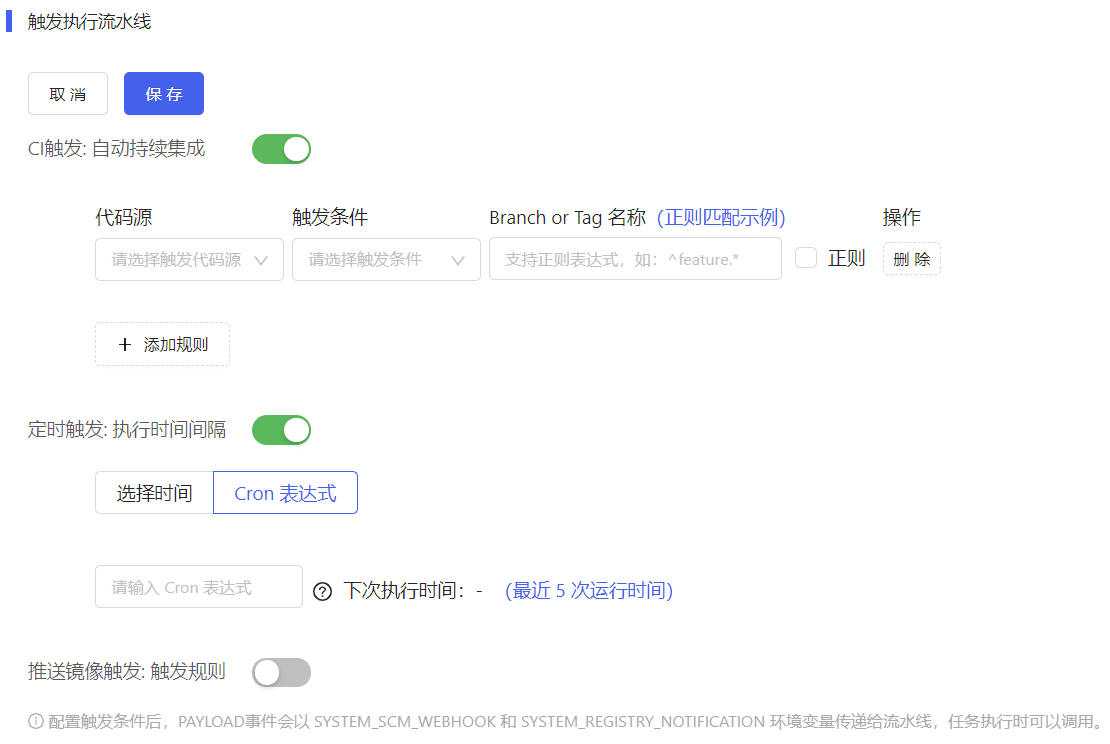
(3) CI触发规则代码源选择当前流水线里的某个任务已经绑定了已激活的代码源,触发条件选择提交代码到Branch、新建tag或合并mergerequest,支持正则匹配。
- 定时触发可以选择每天或每周定时执行流水线;或者配置对应的Cron表达式匹配对应的时间。
- 推送镜像触发:PAYLOAD事件会以SYSTEM_SCM_WEBHOOK和SYSTEM_REGISTRY_NOTIFICATION环境变量传递给流水线,任务执行时可以调用。
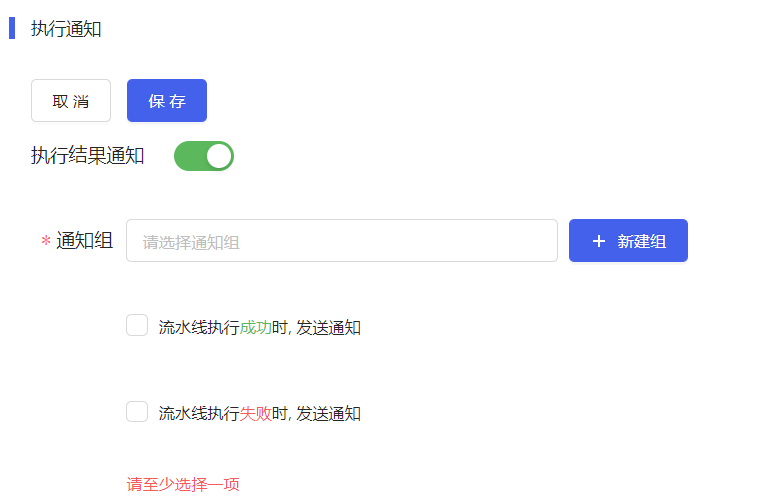
- 执行结果通知:用户可配置是否通知流水线执行结果,用户可使用已有或者新建通知组。开启执行通知后用户需至少选择一项执行通知。配置页面如下图所示。
- 查看代码质量:流水线详情,点击“代码质量”进入代码质量查看页面,可查看每次代码扫码结果以及代码质量趋势图,进行问题跟踪与解决。

若用户想要查看代码质量,则该流水线需包含Sonarqube任务。
点击“执行记录”或流水线详情tab切换到执行记录,如下图所示。
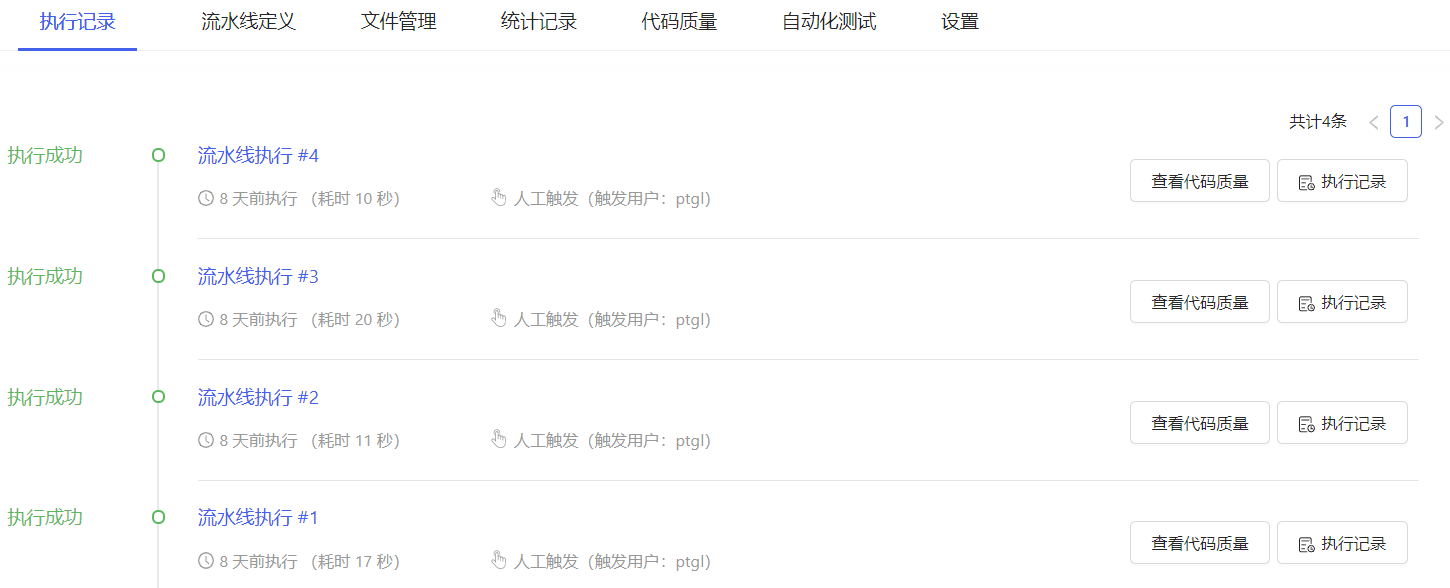
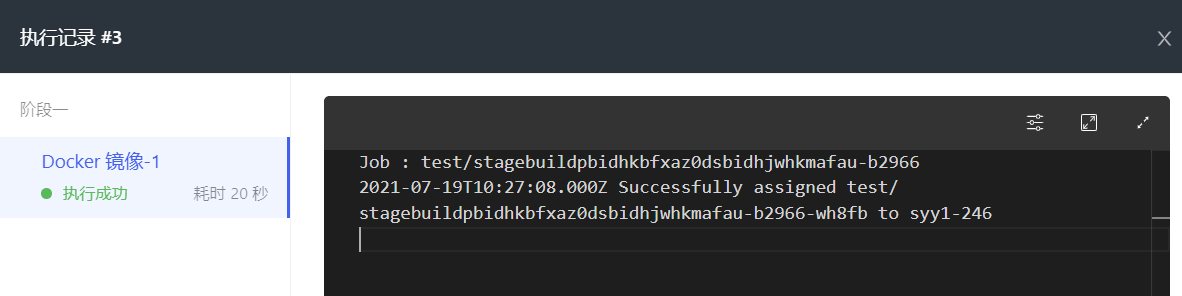
点击任意一条执行记录,进入执行记录详情。可以查看每个任务的执行记录。执行过程中用户可选择是否“停止”或者“暂停执行”。点击右侧查看图标,查看详细记录。
- 跳过:流水线允许跳过任务,当某个任务被设置跳过后,流水线顺序执行时,将会跳过它。如下图所示。点击确定关闭该任务。
- 停止:流水线执行过程中允许手动终止执行。流水线执行过程中,执行记录页面会出现停止按钮。点击<停止>按钮,流水线将会终止执行。
- 编辑流水线:流水线列表,右侧操作点击编辑,弹框如下图。编辑流水线名称、关联代码源和邮件通知,点击<确定>保存。
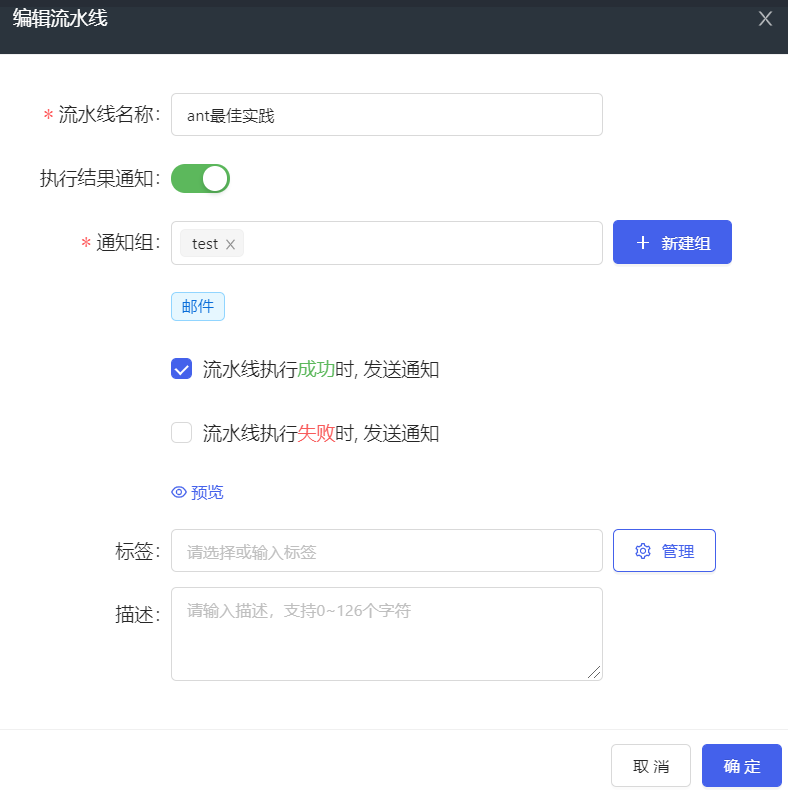
- 编辑阶段:点击阶段右侧操作按钮,选择编辑阶段,编辑阶段名称,点击<确定>保存。
- 编辑任务:点击任务右侧操作按钮,选择编辑,编辑完成后,点击<提交>保存。(参考添加任务)
- 删除流水线:流水线列表,右侧操作点击删除,弹框点击确认即可,删除流水线将清除相关的历史构建数据,且该操作不能被恢复,请确定后再删除。
- 删除阶段:阶段右侧点击操作按钮,选择删除阶段,弹框点击确定即可。
- 删除任务:任务右侧点击操作按钮,选择删除,弹框点击确认即可。
- 执行通知:用户在创建流水线时,或详情页可以设置执行结果通知,如下图所示。
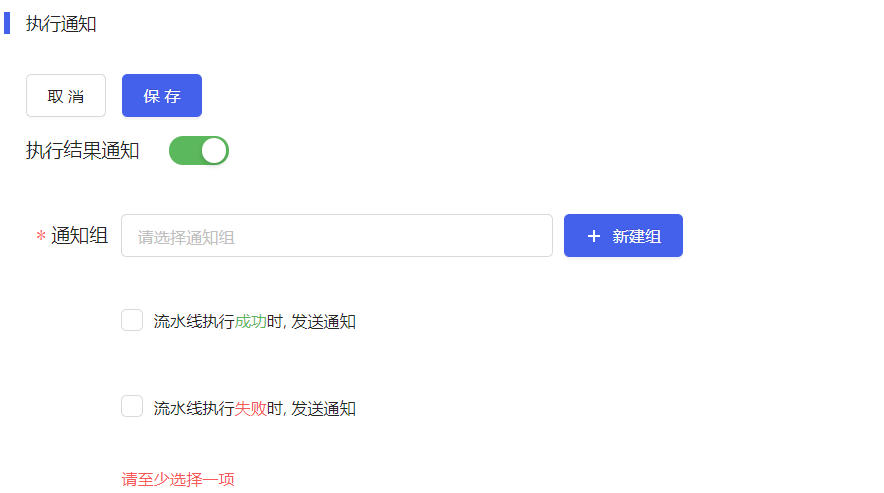
此处可选TCE中意配置的通知组,或者用户可按需在TCE[系统设置/账户中心/通知组]页面新建所需的通知组。流水线执行成功或执行失败时将会发送对应的消息通知。用户配置的通知方式及通知的内容支持预览。
- 删除流水线:在设置页面支持用户删除对应的流水线,流水线删除后系统将清除相关的历史构建数据,删除操作不能被恢复。
- 统计记录:此处显示最近 30 天当前流水线使用情况统计折线图。可以查看该流水线每天执行成功、执行失败、手动触发、CI触发、部署成功、部署失败、普通发布、滚动发布次数。
流水线任务调度策略优化
用户场景:用户希望有 3 个节点只构建流水线,这样不会因为构建导致节点不可用从而影响其他业务的运行; 实现方案:流水线基于Kubernetes的lable和污点特性,实现流水线任务的最优调度方案,具体方案如下所示。
- 开发人员需要做的事只有提交,push,提出MR即可,jira问题的标记可以自动完成,注入备注信息。
- 实现流水线任务之间尽量不分配到同一个节点上。
可以使用命令行添加标签和污点。参数配置列表如下所示。
| 功能 | 配置 |
|---|---|
| 构建节点添加label | kubectllabelnodes[node名称]node-role.kubernetes.io/cicd="" |
| 删除节点label | kubectl label nodes [node名称] node-role.kubernetes.io/cicd- |
| 构建节点添加构建污点 | kubectl taint nodes [node名称] node-role.kubernetes.io/cicd="":NoSchedule kubectl taint nodes [node名称] node-role.kubernetes.io/cicd="":NoExcute |
| 删除污点 | kubectl taint nodes [node名称] node-role.kubernetes.io/cicd:NoSchedule- kubectl taint nodes [node名称] node-role.kubernetes.io/cicd:NoExcute- |
可以使用平台管理节点标签:在[管理工作台/集群管理]菜单,选择某一个主机,进入主机列表tab页签,进行“标签管理”操作。
- 添加标签:标签键输入“kubernetes.io/cicd”,标签值为空即可。
- 删除标签:点击要删除标签上方“×”即可。
- 当没有绑定节点(TCE环境变量没有BIND_BUILD_NODE=true)时,亲和性尽量调度到有node-role.kubernetes.io/cicd:""label的节点。
- 当绑定节点(TCE环境有BIND_BUILD_NODE=true)时,亲和性只调度到有node-role.kubernetes.io/cicd:""label的节点。
- 任务之间(Pod)反亲和性,如果有任务在一个节点执行,另一个节点没有执行任务,就会被调度到没有执行流水线任务的节点上,尽量防止一个节点上跑满所有任务。
- 当节点有node-role.kubernetes.io/cicd:""污点的时候,CI/CD的pod都可以容忍这个污点。
Dockerfile
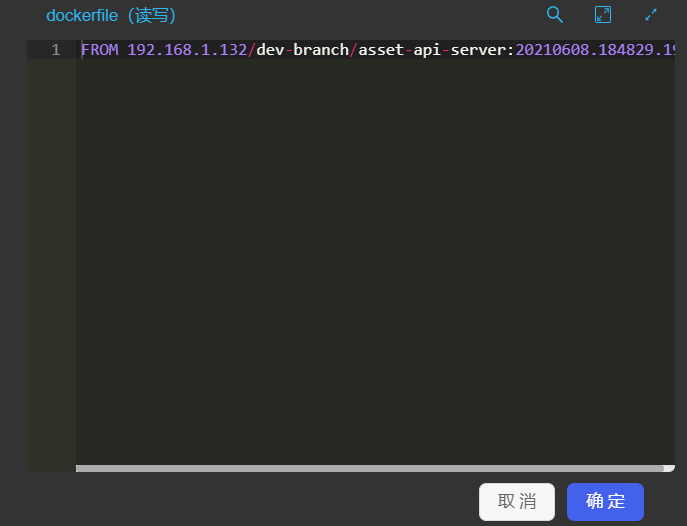
云端Dockerfile:保存用户在流水线过程中创建的云端Dockerfile,方便再次查看、编辑或使用。
点击左侧导航中的Dockerfile,进入云端Dockerfile总览页面,可以查看流水线所有项目中使用到的云端Dockerfile的列表,列表中显示了每个云端Dockerfile所属的流水线和子项目。
点击查看Dockerfile可以查看Dockerfile。点击下拉箭头,并选择编辑Dockerfile,可以对该Dockerfile进行重新编辑。

 京ICP备14045471号
京ICP备14045471号